Tabular Data#
Tabular data are data in a table format, such as an Excel spreadsheet. We often need to work with tabular data. Pandas is a powerful Python library for working with tabular data.
In this part, we will work with real-world data from the European Court of Human Rights OpenData project (ECHR-OD).
ECHR-OD has data sets with cases from the European Court of Human Rights in different formats.
Here, we will work with data from the tabular data file echr_2_0_0_structured_cases.csv, which is in CSV format.
CSV is an abbreviation for “comma separated values”.
You can get the smaller subset from the semester page or the full data set from ECHR-OD.
pandas#
We must first import the pandas library.
import pandas as pd
Note
By convention, pandas is usually imported as pd.
Alternatively, we can import the functions we want to use.
from pandas import Series, DataFrame, read_csv
Pandas has two different data types: Series and DataFrame.
DataFrame#
A pandas DataFrame is a table.
Tables are made up of rows and columns of data, we say they are two-dimensional.
A DataFrame can store numbers and strings as well as other types of data, for example dates.
We can make a DataFrame like this table with made-up data about some fictitious cases:
table = DataFrame([[2, 3, 3],
[5, 4, 0],
[1, 2, 1]]
)
display(table)
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 2 | 3 | 3 |
| 1 | 5 | 4 | 0 |
| 2 | 1 | 2 | 1 |
By default, the rows are numbered. We can add an index to give the rows names instead.
table.index = ['Smith v. Jones',
'Doe v. Doe',
'Jones v. Doe']
display(table)
| 0 | 1 | 2 | |
|---|---|---|---|
| Smith v. Jones | 2 | 3 | 3 |
| Doe v. Doe | 5 | 4 | 0 |
| Jones v. Doe | 1 | 2 | 1 |
We can also give names to the columns.
table.columns = ['time_allotted', 'time_used', 'witnesses']
display(table)
| time_allotted | time_used | witnesses | |
|---|---|---|---|
| Smith v. Jones | 2 | 3 | 3 |
| Doe v. Doe | 5 | 4 | 0 |
| Jones v. Doe | 1 | 2 | 1 |
Reading CSV Files#
Pandas has functions for importing data in many different formats.
Here, we will use CSV files.
To read the data set, we use pandas read_csv() function.
cases = read_csv('cases-100.csv')
Examining Data#
Now, we can examine the data set.
Pandas has a method head() which prints the first five rows of the table.
display(cases.head())
| Unnamed: 0 | application | appno | country.alpha2 | country.name | decisiondate | docname | doctypebranch | ecli | importance | ... | ccl_article=p1-3 | ccl_article=p12-1 | ccl_article=p4-2 | ccl_article=p4-2-1 | ccl_article=p4-4 | ccl_article=p6-1 | ccl_article=p7-1 | ccl_article=p7-2 | ccl_article=p7-3 | ccl_article=p7-4 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | MS WORD | 45498/11 | ru | Russian Federation | NaN | CASE OF SKLYAR v. RUSSIA | CHAMBER | ECLI:CE:ECHR:2017:0718JUD004549811 | 4 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 1 | MS WORD | 18860/07 | ru | Russian Federation | NaN | CASE OF YABLOKO RUSSIAN UNITED DEMOCRATIC PART... | CHAMBER | ECLI:CE:ECHR:2016:1108JUD001886007 | 4 | ... | -1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 2 | MS WORD | 75567/01 | si | Slovenia | NaN | CASE OF OBERWALDER v. SLOVENIA | CHAMBER | ECLI:CE:ECHR:2007:0118JUD007556701 | 4 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 3 | MS WORD | 50031/11 | ru | Russian Federation | NaN | CASE OF RAKHMONOV v. RUSSIA | CHAMBER | ECLI:CE:ECHR:2012:1016JUD005003111 | 4 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 4 | MS WORD | 42894/04 | tr | Turkey | NaN | CASE OF ARAT AND OTHERSv. TURKEY | CHAMBER | ECLI:CE:ECHR:2009:0113JUD004289404 | 4 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 374 columns
Display Function
We can use the Jupyter Notebook function display() to show a nicer format than with print().
This is a large table with 374 columns. Therefore, pandas shows only the first and last columns. We can look at the column names.
There are several interesting columns. We will look at the conclusion columns in the section Relational Operators. Here are just a few examples:
Column |
Content |
|---|---|
|
The name of the case. |
|
The name of the country involved in the case. |
|
Gives the relevant articles for each case. For example, the column |
|
Conclusion for each article. For article 3, the conclusion is in the column |
We can list all the column names like this:
display(list(cases.columns))
Specifying Index Column#
When reading the CSV file, we can specify which column to use as index.
For the ECHR-OD data it makes sense to use docname as index.
cases = read_csv('cases-100.csv', index_col='docname')
display(cases.head())
| Unnamed: 0 | application | appno | country.alpha2 | country.name | decisiondate | doctypebranch | ecli | importance | introductiondate | ... | ccl_article=p1-3 | ccl_article=p12-1 | ccl_article=p4-2 | ccl_article=p4-2-1 | ccl_article=p4-4 | ccl_article=p6-1 | ccl_article=p7-1 | ccl_article=p7-2 | ccl_article=p7-3 | ccl_article=p7-4 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| docname | |||||||||||||||||||||
| CASE OF SKLYAR v. RUSSIA | 0 | MS WORD | 45498/11 | ru | Russian Federation | NaN | CHAMBER | ECLI:CE:ECHR:2017:0718JUD004549811 | 4 | NaN | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| CASE OF YABLOKO RUSSIAN UNITED DEMOCRATIC PARTY AND OTHERS v. RUSSIA | 1 | MS WORD | 18860/07 | ru | Russian Federation | NaN | CHAMBER | ECLI:CE:ECHR:2016:1108JUD001886007 | 4 | NaN | ... | -1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| CASE OF OBERWALDER v. SLOVENIA | 2 | MS WORD | 75567/01 | si | Slovenia | NaN | CHAMBER | ECLI:CE:ECHR:2007:0118JUD007556701 | 4 | NaN | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| CASE OF RAKHMONOV v. RUSSIA | 3 | MS WORD | 50031/11 | ru | Russian Federation | NaN | CHAMBER | ECLI:CE:ECHR:2012:1016JUD005003111 | 4 | NaN | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| CASE OF ARAT AND OTHERSv. TURKEY | 4 | MS WORD | 42894/04 | tr | Turkey | NaN | CHAMBER | ECLI:CE:ECHR:2009:0113JUD004289404 | 4 | NaN | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 373 columns
Getting a Row#
We can use the locator .loc[] to select parts of the table.
First, we select a row using the index.
selection = cases.loc['CASE OF SKLYAR v. RUSSIA']
display(selection)
Unnamed: 0 0
application MS WORD
appno 45498/11
country.alpha2 ru
country.name Russian Federation
...
ccl_article=p6-1 0
ccl_article=p7-1 0
ccl_article=p7-2 0
ccl_article=p7-3 0
ccl_article=p7-4 0
Name: CASE OF SKLYAR v. RUSSIA, Length: 373, dtype: object
Note
Pandas only shows the first and last five columns.
To show all the data, we can convert them to a list().
print(list(selection))
[np.int64(0), 'MS WORD', '45498/11', 'ru', 'Russian Federation', nan, 'CHAMBER', 'ECLI:CE:ECHR:2017:0718JUD004549811', np.int64(4), nan, nan, nan, np.float64(nan), np.float64(nan), np.float64(nan), np.float64(nan), np.float64(nan), np.float64(nan), np.float64(nan), np.float64(nan), np.float64(nan), np.float64(nan), nan, np.float64(nan), np.float64(nan), np.float64(nan), np.float64(nan), np.float64(nan), np.float64(nan), np.float64(nan), nan, nan, np.float64(nan), np.float64(nan), np.float64(nan), np.float64(nan), np.float64(nan), '001-175680', '18/07/2017', '18/07/2017', 'ENG', np.int64(6), 'Third Section', 'Court', 'SKLYAR', 'RUSSIA', np.float64(nan), np.float64(1949.88940429688), 'RUS', nan, np.float64(nan), np.float64(nan), np.float64(nan), np.int64(38), np.False_, np.int64(466267), np.int64(15), np.int64(1), np.int64(1), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(1), np.int64(1), np.int64(1), np.int64(1), np.int64(0), np.int64(0), np.int64(1), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(1), np.int64(1), np.int64(1), np.int64(1), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(1), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(-1), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0), np.int64(0)]
Listing a Column#
We can use the subscript operator to get a column.
selection = cases['country.name']
display(selection)
docname
CASE OF SKLYAR v. RUSSIA Russian Federation
CASE OF YABLOKO RUSSIAN UNITED DEMOCRATIC PARTY AND OTHERS v. RUSSIA Russian Federation
CASE OF OBERWALDER v. SLOVENIA Slovenia
CASE OF RAKHMONOV v. RUSSIA Russian Federation
CASE OF ARAT AND OTHERSv. TURKEY Turkey
...
CASE OF ARTUR PAWLAK v. POLAND Poland
CASE OF PROKHOROV v. UKRAINE Ukraine
CASE OF ALAJOS KISS v. HUNGARY Hungary
CASE OF PSHEVECHERSKIY v. RUSSIA Russian Federation
CASE OF TULESHOV AND OTHERS v. RUSSIA Russian Federation
Name: country.name, Length: 100, dtype: object
We can also use the locator .loc[] for this, then we need to supply two indexes.
If we want to get the entire country.name column, we leave out the indexes and just use a colon.
selection = cases.loc[:, 'country.name']
display(selection)
docname
CASE OF SKLYAR v. RUSSIA Russian Federation
CASE OF YABLOKO RUSSIAN UNITED DEMOCRATIC PARTY AND OTHERS v. RUSSIA Russian Federation
CASE OF OBERWALDER v. SLOVENIA Slovenia
CASE OF RAKHMONOV v. RUSSIA Russian Federation
CASE OF ARAT AND OTHERSv. TURKEY Turkey
...
CASE OF ARTUR PAWLAK v. POLAND Poland
CASE OF PROKHOROV v. UKRAINE Ukraine
CASE OF ALAJOS KISS v. HUNGARY Hungary
CASE OF PSHEVECHERSKIY v. RUSSIA Russian Federation
CASE OF TULESHOV AND OTHERS v. RUSSIA Russian Federation
Name: country.name, Length: 100, dtype: object
Note
We have seen the colon before with lists.
With lists we can also leave out one or both of the indexes.
Without any indexes, we get a copy of the entire list:
list_copy = old_list[:]
Using Numeric Indexes#
Since we opened the table with the argument index_col='docname', it has string indexes like ‘CASE OF SKLYAR v. RUSSIA’. But we can also use numeric indexes with the integer locator .iloc[].
Here we get the first five rows using a range of indexes.
selection = cases.iloc[0:4]
display(selection)
| Unnamed: 0 | application | appno | country.alpha2 | country.name | decisiondate | doctypebranch | ecli | importance | introductiondate | ... | ccl_article=p1-3 | ccl_article=p12-1 | ccl_article=p4-2 | ccl_article=p4-2-1 | ccl_article=p4-4 | ccl_article=p6-1 | ccl_article=p7-1 | ccl_article=p7-2 | ccl_article=p7-3 | ccl_article=p7-4 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| docname | |||||||||||||||||||||
| CASE OF SKLYAR v. RUSSIA | 0 | MS WORD | 45498/11 | ru | Russian Federation | NaN | CHAMBER | ECLI:CE:ECHR:2017:0718JUD004549811 | 4 | NaN | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| CASE OF YABLOKO RUSSIAN UNITED DEMOCRATIC PARTY AND OTHERS v. RUSSIA | 1 | MS WORD | 18860/07 | ru | Russian Federation | NaN | CHAMBER | ECLI:CE:ECHR:2016:1108JUD001886007 | 4 | NaN | ... | -1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| CASE OF OBERWALDER v. SLOVENIA | 2 | MS WORD | 75567/01 | si | Slovenia | NaN | CHAMBER | ECLI:CE:ECHR:2007:0118JUD007556701 | 4 | NaN | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| CASE OF RAKHMONOV v. RUSSIA | 3 | MS WORD | 50031/11 | ru | Russian Federation | NaN | CHAMBER | ECLI:CE:ECHR:2012:1016JUD005003111 | 4 | NaN | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
4 rows × 373 columns
Getting a Single Cell#
We can get a single cell by specifying both the row and column names. We can get the title in the row ‘CASE OF SKLYAR v. RUSSIA’.
selection = cases.loc['CASE OF SKLYAR v. RUSSIA', 'judgementdate']
print(selection)
18/07/2017
Note
Tables are two-dimensional; therefore, we must use two indexes.
Getting Multiple Columns#
We can get multiple columns by specifying their names in a list.
Here, we use the subscript operator, not the locator .loc[].
selection = cases[['country.name', 'judgementdate']]
display(selection)
| country.name | judgementdate | |
|---|---|---|
| docname | ||
| CASE OF SKLYAR v. RUSSIA | Russian Federation | 18/07/2017 |
| CASE OF YABLOKO RUSSIAN UNITED DEMOCRATIC PARTY AND OTHERS v. RUSSIA | Russian Federation | 08/11/2016 |
| CASE OF OBERWALDER v. SLOVENIA | Slovenia | 18/01/2007 |
| CASE OF RAKHMONOV v. RUSSIA | Russian Federation | 16/10/2012 |
| CASE OF ARAT AND OTHERSv. TURKEY | Turkey | 13/01/2009 |
| ... | ... | ... |
| CASE OF ARTUR PAWLAK v. POLAND | Poland | 05/10/2017 |
| CASE OF PROKHOROV v. UKRAINE | Ukraine | 30/11/2006 |
| CASE OF ALAJOS KISS v. HUNGARY | Hungary | 20/05/2010 |
| CASE OF PSHEVECHERSKIY v. RUSSIA | Russian Federation | 24/05/2007 |
| CASE OF TULESHOV AND OTHERS v. RUSSIA | Russian Federation | 24/05/2007 |
100 rows × 2 columns
Missing Data
Here, some of the dates are missing.
Pandas uses NaN to indicate missing numeric data, short for Not a Number.
Matching Multiple Columns#
We can also select multiple columns using string matching on the column names. The matching uses regular expressions, which we will discuss in Regular Expressions.
selection = cases.filter(regex='date', axis='columns')
display(selection)
| decisiondate | introductiondate | judgementdate | kpdate | |
|---|---|---|---|---|
| docname | ||||
| CASE OF SKLYAR v. RUSSIA | NaN | NaN | 18/07/2017 | 18/07/2017 |
| CASE OF YABLOKO RUSSIAN UNITED DEMOCRATIC PARTY AND OTHERS v. RUSSIA | NaN | NaN | 08/11/2016 | 08/11/2016 |
| CASE OF OBERWALDER v. SLOVENIA | NaN | NaN | 18/01/2007 | 18/01/2007 |
| CASE OF RAKHMONOV v. RUSSIA | NaN | NaN | 16/10/2012 | 16/10/2012 |
| CASE OF ARAT AND OTHERSv. TURKEY | NaN | NaN | 13/01/2009 | 13/01/2009 |
| ... | ... | ... | ... | ... |
| CASE OF ARTUR PAWLAK v. POLAND | NaN | NaN | 05/10/2017 | 05/10/2017 |
| CASE OF PROKHOROV v. UKRAINE | 06/11/2006 | 02/03/2004 | 30/11/2006 | 30/11/2006 |
| CASE OF ALAJOS KISS v. HUNGARY | NaN | NaN | 20/05/2010 | 20/05/2010 |
| CASE OF PSHEVECHERSKIY v. RUSSIA | NaN | NaN | 24/05/2007 | 24/05/2007 |
| CASE OF TULESHOV AND OTHERS v. RUSSIA | NaN | NaN | 24/05/2007 | 24/05/2007 |
100 rows × 4 columns
Relational Operators#
Pandas can select data conditionally, using relational operators.
The ECHR-OD case data has a column ccl_article=2.
This column has the value 1 for cases where there was found a violation of Article 2 of the European Convention on Human Rights.
We can use this column in an expression with a relational operator.
cases['ccl_article=2'] == 1
docname
CASE OF SKLYAR v. RUSSIA False
CASE OF YABLOKO RUSSIAN UNITED DEMOCRATIC PARTY AND OTHERS v. RUSSIA False
CASE OF OBERWALDER v. SLOVENIA False
CASE OF RAKHMONOV v. RUSSIA False
CASE OF ARAT AND OTHERSv. TURKEY False
...
CASE OF ARTUR PAWLAK v. POLAND False
CASE OF PROKHOROV v. UKRAINE False
CASE OF ALAJOS KISS v. HUNGARY False
CASE OF PSHEVECHERSKIY v. RUSSIA False
CASE OF TULESHOV AND OTHERS v. RUSSIA False
Name: ccl_article=2, Length: 100, dtype: bool
Boolean Columns
The result is a Boolean column. When we use them with pandas tables, relational operators return Boolean columns. This is just like regular relational operators, except that regular relational operators return a single value.
Relational Operators in Locators#
We can use the result of a relational operator as a filter when selecting cases.
This will select the cases where the Boolean value is True.
selection = cases.loc[cases['ccl_article=2'] == 1]
display(selection)
| Unnamed: 0 | application | appno | country.alpha2 | country.name | decisiondate | doctypebranch | ecli | importance | introductiondate | ... | ccl_article=p1-3 | ccl_article=p12-1 | ccl_article=p4-2 | ccl_article=p4-2-1 | ccl_article=p4-4 | ccl_article=p6-1 | ccl_article=p7-1 | ccl_article=p7-2 | ccl_article=p7-3 | ccl_article=p7-4 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| docname | |||||||||||||||||||||
| CASE OF KUKAYEV v. RUSSIA | 10 | MS WORD | 29361/02 | ru | Russian Federation | NaN | CHAMBER | ECLI:CE:ECHR:2007:1115JUD002936102 | 3 | NaN | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| CASE OF MUDAYEVY v. RUSSIA | 36 | MS WORD | 33105/05 | ru | Russian Federation | NaN | CHAMBER | ECLI:CE:ECHR:2010:0408JUD003310505 | 4 | NaN | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| CASE OF KALLIS AND ANDROULLA PANAYI v. TURKEY | 62 | MS WORD | 45388/99 | tr | Turkey | NaN | CHAMBER | ECLI:CE:ECHR:2009:1027JUD004538899 | 4 | NaN | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
3 rows × 373 columns
Conclusion Columns
The conclusions of each case are listed in the columns starting with ccl_article.
For Article N, the column name is ccl_article=N.
These columns have 3 possible values:
Value |
Meaning |
|---|---|
1 |
violation |
-1 |
no violation |
0 |
no conclusion / not relevant |
Likewise, we can select cases where there was found no violation of Article 5 § 3.
selection = cases.loc[cases['ccl_article=5-3'] == -1]
display(selection)
| Unnamed: 0 | application | appno | country.alpha2 | country.name | decisiondate | doctypebranch | ecli | importance | introductiondate | ... | ccl_article=p1-3 | ccl_article=p12-1 | ccl_article=p4-2 | ccl_article=p4-2-1 | ccl_article=p4-4 | ccl_article=p6-1 | ccl_article=p7-1 | ccl_article=p7-2 | ccl_article=p7-3 | ccl_article=p7-4 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| docname | |||||||||||||||||||||
| CASE OF PAWLAK v. POLAND | 47 | MS WORD | 39840/05 | pl | Poland | NaN | CHAMBER | ECLI:CE:ECHR:2008:0115JUD003984005 | 4 | NaN | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
1 rows × 373 columns
Finding Text#
We can’t use a relational operators with text strings. Instead, we use .str.contains():
cases.loc[cases['country.name'].str.contains('Germany')]
| Unnamed: 0 | application | appno | country.alpha2 | country.name | decisiondate | doctypebranch | ecli | importance | introductiondate | ... | ccl_article=p1-3 | ccl_article=p12-1 | ccl_article=p4-2 | ccl_article=p4-2-1 | ccl_article=p4-4 | ccl_article=p6-1 | ccl_article=p7-1 | ccl_article=p7-2 | ccl_article=p7-3 | ccl_article=p7-4 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| docname | |||||||||||||||||||||
| CASE OF MARC BRAUER v. GERMANY | 41 | MS WORD | 24062/13 | de | Germany | NaN | CHAMBER | ECLI:CE:ECHR:2016:0901JUD002406213 | 3 | NaN | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| CASE OF BARTHOLD v. GERMANY (ARTICLE 50) | 53 | MS WORD | 8734/79 | de | Germany | NaN | CHAMBER | ECLI:CE:ECHR:1986:0131JUD000873479 | 2 | NaN | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| CASE OF KLINKENBUSS v. GERMANY | 90 | MS WORD | 53157/11 | de | Germany | NaN | CHAMBER | ECLI:CE:ECHR:2016:0225JUD005315711 | 3 | NaN | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
3 rows × 373 columns
Combining Conditions#
With pandas, we can’t use and to combine expressions, instead we must use &:
cases.loc[cases['country.name'].str.contains('Germany') & (cases['importance'] >= 3)]
| Unnamed: 0 | application | appno | country.alpha2 | country.name | decisiondate | doctypebranch | ecli | importance | introductiondate | ... | ccl_article=p1-3 | ccl_article=p12-1 | ccl_article=p4-2 | ccl_article=p4-2-1 | ccl_article=p4-4 | ccl_article=p6-1 | ccl_article=p7-1 | ccl_article=p7-2 | ccl_article=p7-3 | ccl_article=p7-4 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| docname | |||||||||||||||||||||
| CASE OF MARC BRAUER v. GERMANY | 41 | MS WORD | 24062/13 | de | Germany | NaN | CHAMBER | ECLI:CE:ECHR:2016:0901JUD002406213 | 3 | NaN | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| CASE OF KLINKENBUSS v. GERMANY | 90 | MS WORD | 53157/11 | de | Germany | NaN | CHAMBER | ECLI:CE:ECHR:2016:0225JUD005315711 | 3 | NaN | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
2 rows × 373 columns
Important
Remember to use parentheses around the conditions with &. Otherwise, you will get unexpected results.
The isin() Method#
With basic Python data types, we can check if they occur in a list with the operator in, for example 5 in [0, 1] is False.
Likewise, pandas has the method .isin() for checking if table values occur in a list.
We can use this for example for finding cases where the conclusion is “violation” or “no violation”, filtering out cases where an article is not relevant.
As the table Conclusion Values shows, the value is 1 for “violation” or -1 for “no violation”. Again, we try with Article 5 § 3.
selection = cases.loc[cases['ccl_article=5-3'].isin([-1, 1])]
display(selection)
| Unnamed: 0 | application | appno | country.alpha2 | country.name | decisiondate | doctypebranch | ecli | importance | introductiondate | ... | ccl_article=p1-3 | ccl_article=p12-1 | ccl_article=p4-2 | ccl_article=p4-2-1 | ccl_article=p4-4 | ccl_article=p6-1 | ccl_article=p7-1 | ccl_article=p7-2 | ccl_article=p7-3 | ccl_article=p7-4 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| docname | |||||||||||||||||||||
| CASE OF PAWLAK v. POLAND | 47 | MS WORD | 39840/05 | pl | Poland | NaN | CHAMBER | ECLI:CE:ECHR:2008:0115JUD003984005 | 4 | NaN | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| CASE OF POPLAWSKI v. POLAND | 56 | MS WORD | 28633/02 | pl | Poland | NaN | CHAMBER | ECLI:CE:ECHR:2008:0129JUD002863302 | 4 | NaN | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| CASE OF PSHEVECHERSKIY v. RUSSIA | 98 | MS WORD | 28957/02 | ru | Russian Federation | NaN | CHAMBER | ECLI:CE:ECHR:2007:0524JUD002895702 | 4 | NaN | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
3 rows × 373 columns
Selecting by Year#
We can select cases by the decision date.
First, we must convert the decisiondate column to machine-readable format.
cases['decisiondate'] = pd.to_datetime(cases['decisiondate'], dayfirst = True)
Tip
We specify the date format with the argument dayfirst = True.
There is also an argument yearfirst.
Note
Python has the built-in library datetime for handling time and dates.
But when we use pandas, we usually only need pandas’ to_datetime() function.
Now, we can use the year from the decision date with a relational operator.
selection = cases.loc[cases['decisiondate'].dt.year == 2005]
display(selection)
| Unnamed: 0 | application | appno | country.alpha2 | country.name | decisiondate | doctypebranch | ecli | importance | introductiondate | ... | ccl_article=p1-3 | ccl_article=p12-1 | ccl_article=p4-2 | ccl_article=p4-2-1 | ccl_article=p4-4 | ccl_article=p6-1 | ccl_article=p7-1 | ccl_article=p7-2 | ccl_article=p7-3 | ccl_article=p7-4 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| docname | |||||||||||||||||||||
| CASE OF KOTLYAROV v. UKRAINE | 15 | MS WORD | 43593/02 | ua | Ukraine | 2005-11-22 | CHAMBER | ECLI:CE:ECHR:2005:1213JUD004359302 | 4 | 25/10/2002 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| CASE OF FRYCKMAN v. FINLAND | 20 | MS WORD | 36288/97 | fi | Finland | 2005-11-15 | CHAMBER | ECLI:CE:ECHR:2006:1010JUD003628897 | 4 | 21/05/1997 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| CASE OF DEBONO v. MALTA | 34 | MS WORD | 34539/02 | mt | Malta | 2005-05-03 | CHAMBER | ECLI:CE:ECHR:2006:0207JUD003453902 | 4 | 06/09/2002 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| CASE OF GERASIMENKO v. RUSSIA | 76 | MS WORD | 24657/03 | ru | Russian Federation | 2005-10-25 | CHAMBER | ECLI:CE:ECHR:2005:1117JUD002465703 | 4 | 12/09/1999 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
4 rows × 373 columns
Aggregating Data#
Pandas has various functions for aggregating data.
For example, we can count the number of occurrences of different values with value_counts().
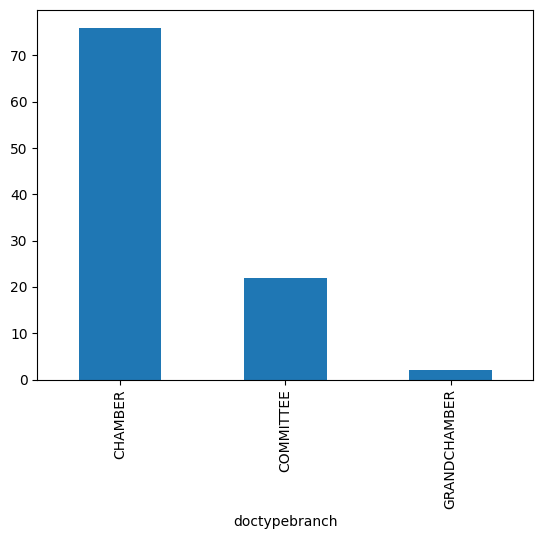
The column doctypebranch contains the type of deciding body for the case.
selection = cases['doctypebranch'].value_counts()
print(selection)
doctypebranch
CHAMBER 76
COMMITTEE 22
GRANDCHAMBER 2
Name: count, dtype: int64
Visualizing Data#
We can also plot our results. Here we continue working with our selection.
selection.plot(kind='bar')
<Axes: xlabel='doctypebranch'>
Sums#
Pandas has a function for calculating the sum of columns or rows.
Since our data uses the number 1 to indicate True, we can count matching cases simply by summing the ones.
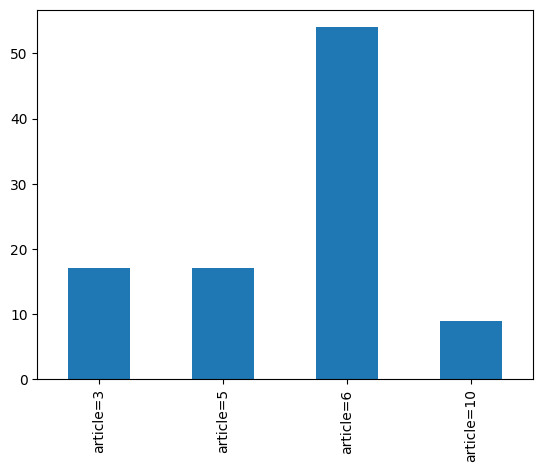
We can find the number of cases where Article 3 applies by summing the column article=3.
result = cases.loc[:, 'article=3'].sum()
print(result)
17
We can also sum the values of multiple columns at once.
result = cases.loc[:, ['article=3', 'article=5', 'article=6', 'article=10']].sum()
And plot the result.
result.plot(kind='bar')
<Axes: >
Choosing Axis#
As we have seen, the method .sum()without any parameters will calculate the sum downwards, along the index of the table.
We are adding together the rows of the table.
result = cases.loc[:, ['article=3', 'article=5', 'article=6', 'article=10']].sum()
display(result)
article=3 17
article=5 17
article=6 54
article=10 9
dtype: int64
We get the same result if we specify the parameter axis = 'index'.
This is because 'index' is the default value for the parameter axis.
result = cases.loc[:, ['article=3', 'article=5', 'article=6', 'article=10']].sum(axis='index')
display(result)
article=3 17
article=5 17
article=6 54
article=10 9
dtype: int64
We can also add together the columns of the table.
To do this, we must change the direction to axis = 'column'.
result = cases.loc[:, ['article=3', 'article=5', 'article=6', 'article=10']].sum(axis='columns')
display(result)
docname
CASE OF SKLYAR v. RUSSIA 2
CASE OF YABLOKO RUSSIAN UNITED DEMOCRATIC PARTY AND OTHERS v. RUSSIA 0
CASE OF OBERWALDER v. SLOVENIA 1
CASE OF RAKHMONOV v. RUSSIA 1
CASE OF ARAT AND OTHERSv. TURKEY 1
..
CASE OF ARTUR PAWLAK v. POLAND 1
CASE OF PROKHOROV v. UKRAINE 1
CASE OF ALAJOS KISS v. HUNGARY 0
CASE OF PSHEVECHERSKIY v. RUSSIA 1
CASE OF TULESHOV AND OTHERS v. RUSSIA 0
Length: 100, dtype: int64
The result is a column with 100 items. These are the number of relevant articles (of the four we selected) for the 100 cases.
Series#
A pandas Series is a list of values, similar to a Python list.
When we selected a single row or column above, the result was a Series.
We can select a single column from our small example DataFrame.
column = table['time_used']
print(column)
Smith v. Jones 3
Doe v. Doe 4
Jones v. Doe 2
Name: time_used, dtype: int64
We can select a row with .loc[ ].
row = table.loc['Doe v. Doe']
print(row)
time_allotted 5
time_used 4
witnesses 0
Name: Doe v. Doe, dtype: int64
If we need to, we can also make a Series from scratch:
row = Series([3, 1, 5])
print(row)
0 3
1 1
2 5
dtype: int64